前端静态 Markdown 博客网站实现
2023/7/7
本文主要介绍了本站的实现原理,本文实现仅供参考。
如果你访问过本站,你可能会对本站作为一个部署于 Github Page 上的静态网站,是如何实现类似于动态网站的功能感到好奇。如果你看过了本站的部分代码,你可能也会对本站是如何渲染 Markdown 文档感到好奇。
本文主要分为三个部分:
- Markdown 文档的编译(md -> html)
- 网站静态文件索引的实现(indexing)
- 前端路由的实现(hash)及路由到静态文件的映射
Markdown 文档的编译
这一部分其实算是本站最复杂的一部分,因为这个简易的编译器是我自己写的(😀
当然你如果嫌麻烦之类的,也可以用现成的 npm 包(e.g. marked),效果相同。
为了防止文章篇幅过长,这里就不贴我的代码实现了,贴个 Github 上的代码地址,有感兴趣的小伙伴可以看一下~~
网站静态文件索引的实现
这一部分又可以分成三个小部分:
- 静态文件遍历
- 分页函数实现
- 创建并写入索引数据
在完成了这三个部分之后,你可以参考这里,将代码整合到一个脚本中,在你每次对静态文件进行改动(增添、删减等)时对其调用。
静态文件遍历
这一步非常简单,下面直接贴上我的代码实现:
const fs = require("node:fs")
// input: "./static/" // 这里是静态文件文件夹的路径
// returns: [ 'test.md', [ 'test_folder', [] ] ]
function readDir(path) {
const result = []
const dirContent = fs.readdirSync(path)
// 根据文件最后修改时间进行排序,
// 把最新的文件放在最前面。
dirContent.sort((a, b) =>
fs.statSync(path + b).mtime.getTime() - fs.statSync(path + a).mtime.getTime())
// 遍历文件夹下所有项目
for (const item of dirContent) {
// 当前项目的实际路径
const currentPath = path + item
const stat = fs.statSync(currentPath)
if (stat.isDirectory()) {
// 忽略以 '.' 开头的文件夹,因为在我的项目中,以 '.' 开头的文件夹
// 主要用于存放图片等资源,不应被索引。
if (!item.startsWith(".")) {
result.push([item, readDir(currentPath + "/")])
}
} else {
result.push(item)
}
}
return result
}
分页函数实现
这一步是为了防止当网站文章过多时导致索引文件过大。下面贴上代码实现:
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
// ||
// ||
// \/
// [[1, 2, 3, 4, 5, 6, 7, 8, 9, 10], [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]
// 单页的项目数量
const pageCount = 10
function slicing(items) {
if (items.length <= pageCount) {
return [items]
} else {
const slices = []
while (items.length > pageCount) {
slices.push(items.splice(0, pageCount))
}
slices.push(items)
return slices
}
}
创建并写入索引数据
这一步主要是在处理第一步生成的数据,将每个文件夹下的每一层放到一个索引对象中。我们用一棵树来具体解释一下:
root // 这是存放静态文件的根目录
|
-------------------
| |
dir1 dir2 // 假设下面有两个文件夹
| |
--------- ----------
| | | |
file1 dir3 file2 dir4
| |
--------- ----------
| | | |
file5 file6 file7 file8
则最终会生成大概这样的结构:
[
["dir1/", "dir2/"], // 对于 `root` 的索引
["file1", "dir3/"], // 对于 `dir1` 的索引
["file5", "file6"], // 对于 `dir3` 的索引
// 以此类推 ...
]
下面是具体的代码实现:
function indexing(currentDir, currentName) {
// 当前文件夹的索引的数据
const currentDirFiles = []
for (const item of currentDir) {
if (typeof item == "string") {
// 如果遇到文件,直接加入索引数据
currentDirFiles.push(item)
} else {
// 如果遇到文件夹,则以 '/' 结尾后再加入索引数据
currentDirFiles.push(item[0] + "/")
// 递归读取文件夹
indexing(item[1], `${currentName}+${item[0]}`)
}
}
// 对当前文件夹索引进行分页处理
const sliced = slicing(currentDirFiles)
// 总页数
const count = sliced.length
// 遍历每一页并用 `index` 标上页码
let index = 0
for (const slice of sliced) {
index += 1
// 这里是我自定义的文件名格式
// 示例:
// static_1
// static+Web 前端_1
fs.writeFileSync(`${indexPath}${currentName}_${index}`, JSON.stringify({
total: count,
current: index,
content: slice,
}))
}
}
前端路由的实现及路由到静态文件的映射
由于本项目的目标是一个静态站点,故使用基于location.hash的路由实现。
这里放出我的实现,仅供参考。
async function fetchJSON(path) {
return await fetch(path)
.then(res => res.json())
}
async function fetchMD(path) {
return await fetch(path)
.then(res => res.body)
.then(async body => {
const reader = body.getReader()
const decoder = new TextDecoder('utf-8');
let totalData = "";
const processor = (result) => {
if (result.done) {
return totalData
}
totalData += decoder.decode(result.value, { stream: true })
return reader.read().then(processor);
}
const result = await reader.read();
return processor(result);
})
}
// 本项目默认的索引文件位置
const indexDirPath = "./.index/"
async function hashEvent() {
if (location.hash) {
// 去掉 '#' 字符
const hash = location.hash.slice(1)
if (hash.endsWith("/")) {
// 定义以 '/' 结尾的路径为 文件夹
const splited = hash.split("/").slice(0, -1)
// 这里根据前面定义的索引文件名称格式,对 hash 进行处理,
// 得到目标文件夹对应的索引文件
const indexFilePath = indexDirPath + splited.join("+") + "_" + globalThis.CurrentPage
const indexing = await fetchJSON(indexFilePath)
// 对获取到的索引文件进行渲染,渲染过程略
// 相当于进入了子文件夹。
indexRender(indexing)
}
if (hash.endsWith(".md")) {
// 定义以 ".md" 结尾的路径为 文章
const articleContent = await fetchMD("./" + hash)
// 这里对获取到的 Markdown 文档进行解析、编译。
const structure = mdResolver(articleContent)
// 对编译结果进行渲染,渲染过程略
// 相当于进入文章页面。
mdRender(structure)
}
} else {
// "static/" 为本项目的静态文件文件夹路径。
// 当无 hash 时,将 hash 调整为 "static/"
// 从而加载静态文件根目录,相当于加载首页。
location.hash = "static/"
}
}
// 最后,添加事件监听,当页面加载时和 hash 改变时调用上述函数。
// 页面加载时调用是为了更便于分享网站上的文章。
window.onload = hashEvent
// hash 改变时调用是为了便于控制在按键点击时改变界面。
window.addEventListener("hashchange", hashEvent)
项目预览
最后,当你写完一篇博客的时候,肯定会有想要先在本地预览的需求。
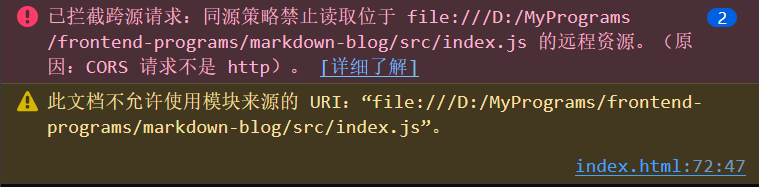
首先,如果你的代码组织使用了 ES Module,你是无法通过在浏览器直接打开 HTML 文件的方式来预览的,即使这个项目基本所有的代码都写在前端。如下图,你大概率会因为同源策略而无法加载索引文件。浏览器报错如下图所示:
我的解决方式
在本地安装 Express npm i express`。
在项目根目录新建preview.js
const express = require("express")
const app = express()
const port = 3000
// 这里不设成根目录是因为对于 Github Page 托管的页面,
// 其首页很可能也是不在网站根目录的。
app.use("/preview", express.static("./"))
app.listen(port, () => {
console.log(`http://localhost:${port}/preview/`)
})
运行脚本,在浏览器中打开http:localhost:3000/preview/,就可以看到网站的预览啦!
为了方便,你还可以将第二阶段的构建脚本和这个预览脚本写到package.json中,方便调用。
{
"name": "repo-name",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"preview": "node preview.js", // <--
"build": "node builder.js" // <--
},
"dependencies": {
"express": "^4.18.2"
}
}
本文到此结束,感谢阅读!